Intent-Aware Semantic Search: An Architectural Approach

The problem setup
I worked in a startup focusing on open-source data-platforms. As you might guess, building visibility is one of the first things you need to do in startups, and this was not different.
As the topic was hot I thought it would be rather easy to fill social media with content referencing news, articles, blogs etc. and make a point for open-source platforms. Well, I was wrong on that. It was painful to find relevant articles to refer to. I couldn’t find any tool that would follow the current thing and understand my intention. Keyword-based tools are everywhere, but semantic search just is not there.
After quitting the startup I needed something to do and decided to implement this service. A simple service where user provides a very brief description what he or she is interested in, and the platform would deliver relevant information.
It turned out to be an enjoyable journey.
So, I made the decision in the very beginning that the user only needs to provide very little information for the best user experience. Furthermore, I decided to target the service to SMB-business leaders. These were the founding architectural decisions that all was built on.
When you think about the requirement that a very short piece of text should yield to a very accurate result, you see immediately it wouldn’t be easy. It wasn’t, I had to iterate quite a lot to make it work. But it does work as of today.
The embedding problem
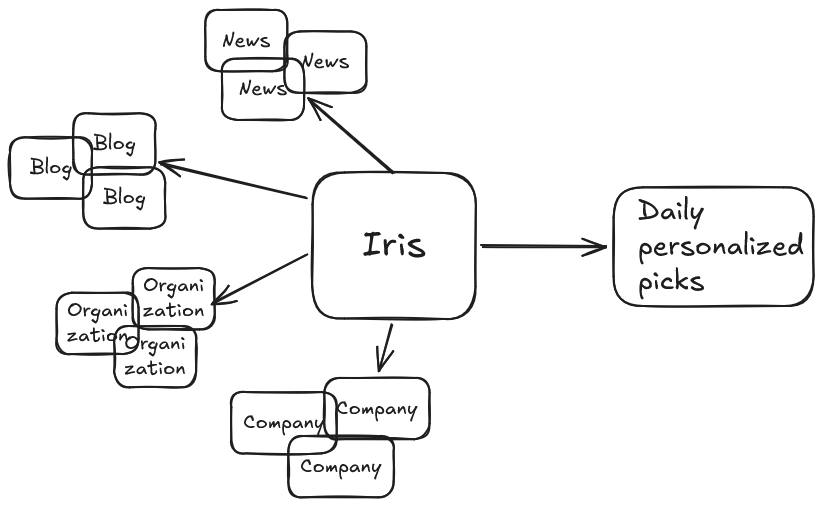
I started this by building a RSS-service that would fetch RSS-feeds from here and there. After a while I had a stream of around 2000 articles per day flowing into the system. This was enough to start building the actual logic, i.e. AI.
When you have mass of this scale, it is rather clear that you can’t just feed everything to a frontier-model. Say you have 2000 articles and 100 users, that would total to 200 000 analysis per day. Far from feasible, and filthy expensive too. Local models don’t really help much here. I wanted something simple, and the obvious tool here is embedding.
Embedding the RSS-items and contents is rather easy and standard practise. After some tests I ended up forming a string “HEADLINE: <headline> CONTENT: <truncated article>”. The content alone didn’t work too well, and the same for headline. I had to include both and I found out that it improves accuracy, if I truncated the article.
I think it would be worth to test also “HEADLINE: <headline> <headline> CONTENT: <truncated article>”. The headline often provides a succinct presentation of the contents and putting weight on that could push the embedding more to the right corner of the embedding space. The potential problem is click-bait-headline. They don’t really position the article anywhere; hence I left this test in the backlog.
As for the model, the first criterion was clear. It must understand Finnish language. I did some testing and was a bit surprised that the performance differences were rather big. I ended up with the model e5-multilingual-large. The embedding space is 1024-dimensions and it does work with Finnish language quite well. The speed is ok, could be faster but with my volumes it goes.
From implicit to explicit
So we had the basic setup up and running. And I tried the obvious way, embed the user query and do vector search in the article database.
Hopeless. It matched nothing. I mean… it was like shooting in the dark. It dug up articles with no real relevance, and missed articles with clear relevance.
Soon I realized that it actually works just as defined, I just used it all wrong. The embedding is trained to put similar texts close to each other, and non-similar far from each other. If you have text, that covers two distinct areas like agriculture and theoretical physics, the embedding should place the article in a place that is close to agriculture and theoretical physics.
When you now look at user queries
“I am a freelancer IT-consultant. I am interested in open-source data-platforms, data sovereignty, EU-legislation in this area and political statements about data sovereignty”,
the problem is evident. The explicit structure covers “open-source data-platforms”, “data sovereignty”, “EU-legislation” and “political statements”. When you embed this, you (although embedding is “semantic preserving”) embed terms and words, and you end up in a place in the embedding space where the text is close to the core areas it mentions and potential synonyms.
But the user intention is not explicit, it is implicit. It is not worded at all in the query. You need to understand what IT-freelancer is interested in, not just on synonyms around the text. In this case the user is hardly interested in agricultural EU-legislation, or political statements in general etc.
Ok, luckily this is fixable. I solved this in two parts (it took some time to figure this out). First, I use a frontier model to put context on the user query. And this is precisely why I ask the user to define his or her profession. It provides the context needed to translate the intention into vector searchable form.
It is rather easy. I just tell frontier model to enrich the criteria, and it does. The result is usually a long piece of text that brings up the main terms. It transfers the implicit intention to explicit terms and topics.

Next problem is that this processed version contains a lot of text and embedding long texts makes it close to everything it mentions. The embedding is not accurate in this sense. It would match nothing with high relevance, but a lot with low relevance.
Because of this the next step uses another frontier-model to separate topics from the enriched query. It simply splits the text into, say, 5-30 separate topics. This phase ensures that we can build queries that actually match something.
An embedding of a simple topic didn’t work too well, so after some testing I ended up using frontier model third time to create a term vector for each topic. The length is around 500-600 characters, which is about the double I expected to work the best. This improved the recall quite a lot. One just has to be careful to prompt the model to keep the terms within the boundaries, to ensure that the resulting term vectors are as orthogonal to each other as possible.
In the last step I embed the term vectors. And we are ready for the search and curation phase.
The quality vs. cost balance
This project is all from my wallet. I setup the environment in Azure and use PostgreSQL, Python, Linux and frontier models. Capacity is really not an issue, the setup doesn’t cost too much (perhaps 50$/mnth), but after quitting my job, I had to cut all costs I could, and so I did. And the LLM-costs can get out of hand quite fast. Because of this reality, I studied different options.
The usual pipeline in the retrieval phase is
- Pre-select with vector search
- Pre-select with term search like BM25
- Do rerank with a reranker
- Do a final rank with a bigger/frontier model.
As it turned out, the BM25 is not supported by PostgreSQL. I did some testing with the tools it has, but I soon found out this is not that important. The fine-tuning of the criterion text to term vector seemed to do the trick already, hence I ditched the term-search altogether. Should this service go commercial at some point, I might rethink, but for now my pipeline does not use any term-search at all.
Now, the vector search is easy. I use the term-vectors (or embedding, to be specific) and search the article space. The search is for each term-vector separately and I take only the best matches, i.e. there is no balancing between different term-vector scores. This is because the vectors are defined to be as orthogonal as possible. Putting some weights in would just blur the picture. And some testing supports this hypothesis.
The hard part was what to do with the pre-fetched articles. It was clear I had to take top-250 to cover all relevant articles. But feeding 250 articles to frontier model would be far too expensive.
The industry standard is to use reranker-model to rerank articles and cut the probable noise out. Reranker is a sort of stronger version of embedding. It has a better grip in the semantics and context, but falls far from any LLM. They are tuned for this specific task.
I did try Cohere reranker. They provide commercial API for reranking that I tested out. It was very fast, very accurate and very expensive. Quality matched my criterions, price did not. So I had to look elsewhere.
After some search I tried Jina reranker, both commercial API and local instance. The commercial API did not meet the quality, and the local instance was extremely slow on CPU (can’t afford GPU).
Rerankers were a hard bite. I was not able to come up with anything useful with them. My guess is that Finnish language is the barrier here. Most rerankers are tuned for larger languages.
After a while I came up with a plan to use the cheapest possible LLM to do the reranking step. Gpt-4o-mini is very cheap, fast and definitely better in this use case than the rerankers I tested.
So now I feed this mini-model a batch of 10-articles (title+truncated article) and prompt it to match the article with user query. It does this by scoring the articles with scale 1-100.

I had some quality issues with the mini-model, but the old trick fixed that. I ask it to provide reasoning behind the scores. I don’t use the justifications anywhere, but requesting them seems to improve the quality quite a lot.
So the pipeline now feeds 250 articles to Gpt-4o-mini in batches of ten articles. This is fast and not that expensive.
But it is not enough. Just taking the top 10-15 articles often provides a very homogeneous view over the news. Even though the system handles duplicates, having today over 1800 information sources results to articles that go around the same topic in slightly different ways. Not many want that.
I ended up taking top-50 articles from the Gpt-4o-mini (per scores) and feed them to Gpt-4o for final curation. It cuts off articles too similar to each other, balances the overall view over the day and uses the user original criterion for the task.
Results and learnings
This project taught me that architectural decisions matter more than model selection. The breakthrough wasn't finding a better embedding model. It was realizing that user intent needs translation before it can be searched.
Key takeaways:
- Short queries ≠ short embeddings (context expansion is critical)
- Orthogonal term vectors > single enriched query
- Gpt-4o-mini can replace expensive rerankers for non-English languages
- Diversity curation is as important as relevance scoring
I started this project as just a simple MVP to see I could pull it off. Today the service is available to the public, but be aware, it only follows Finnish information. Also, it only accepts a limited number of users. See https://www.irisfeed.com
If you're building similar intent-aware systems, feel free to reach out. I'm happy to discuss the architecture.