Building Controllable Latent Representations with Typed Autoencoders


Earlier we discussed latent spaces (in the context of AE and VAE). Let's explore a bit more deeply how to actually make the latent space useful by explicitly defining semantics of named coordinates.
So far latent spaces have just been vector spaces with no clear inherent semantic structure. You can locate a subspace that contains description of a digit, and the further you drift from that location, the "less digit" you get. None of the directions don't really carry any clear semantics.
Let's try to add a rotational element in the latent space. Namely, assume we have some latent representation \(z\) of some image \(x\). We add a coordinate in latent space with which we can rotate the decoded image, i.e. decoder\((z,\theta)\) results in an image \(x\) rotated with \(\theta\).
In literature this subject is called "disentangled representations".
Again, you can find the code from my GitHub under DeepEnd and deep_learning/typed_ae.
Model Architecture
Now that we saw and understood the beautiful theory, we are licensed to break it. And that license we will use with no hesitation.
Let's define a simple autoencoder architecture with a small variation. We define a separate rotation head.
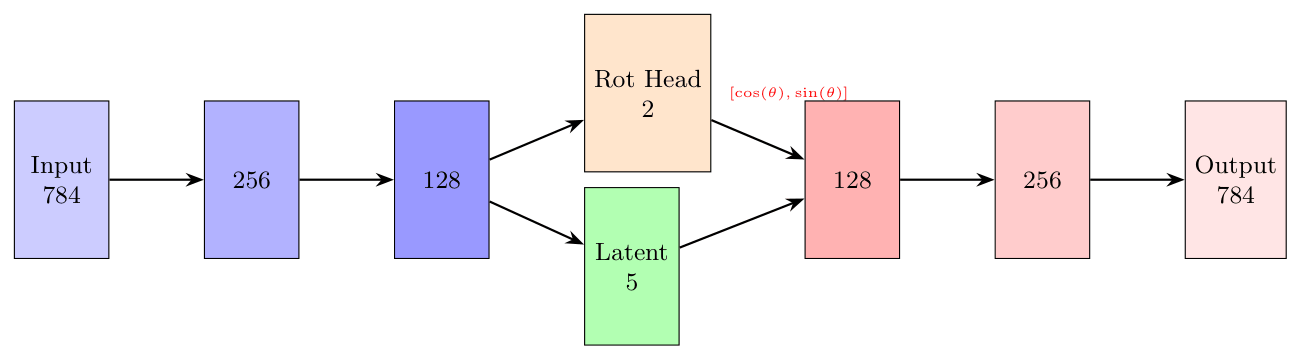
The rotation head encodes rotation into a vector \((\cos(\theta),\sin(\theta))\) and we use a special class for it. The motivation becomes clear later.
class CyclicBottleneck(nn.Module):
def __init__(self, in_features):
super().__init__()
self.fc = nn.Linear(in_features, 2)
def forward(self, x):
raw = self.fc(x)
normalized = F.normalize(raw, p=2, dim=-1)
return normalized
The actual model is, again, straightforward. We define encoder and decoder separately, and in the bottleneck-layer we use the CyclicBottleneck.
class TypedAE(nn.Module):
def __init__(self, latent_dim=5):
super().__init__()
self.latent_dim = latent_dim
self.encoder_backbone = nn.Sequential(
nn.Linear(28*28, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU()
)
self.head_rot = CyclicBottleneck(128) # Rotation (2D)
self.head_latent = nn.Linear(128, latent_dim) # Rest latent
# Decoder takes: 2 (rot) + latent_dim
self.decoder = nn.Sequential(
nn.Linear(2 + latent_dim, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, 28*28),
nn.Sigmoid()
)
def forward(self, x):
h = self.encoder_backbone(x.view(x.size(0), -1))
z_rot = self.head_rot(h)
z_latent = self.head_latent(h)
z_combined = torch.cat([z_rot, z_latent], dim=-1)
recon = self.decoder(z_combined).view(x.size(0), 1, 28, 28)
return recon, z_rot, z_latent
Notice the naming. The "typed" means that we are trying to build some semantics within the latent space, i.e. we are trying to define coordinates in the latent space that provide us some meaningful control over the generated image.
Our training now consists of three separate phases. First we train the autoencoder to encapsulate the images to latent space. We keep the rotation head constant at this phase. This ensures the image is encoded to the other dimensions.
model = TypedAE().to(device)
transform = transforms.Compose([
transforms.ToTensor(),
])
train_dataset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
for epoch in range(epochs):
model.train()
total_loss = 0
for batch_idx, (images, labels) in enumerate(tqdm(train_loader, desc=f"Epoch {epoch+1}/{epochs}")):
images = images.to(device)
optimizer.zero_grad()
# Forward pass - NO rotation
h = model.encoder_backbone(images.view(images.size(0), -1))
z_latent = model.head_latent(h)
# z_rot = zero (no rotation)
z_rot = torch.zeros(images.size(0), 2).to(device)
z_rot[:, 0] = 1.0 # cos(0) = 1
z_combined = torch.cat([z_rot, z_latent], dim=-1)
recon = model.decoder(z_combined).view(images.size(0), 1, 28, 28)
# Loss
loss = nn.functional.mse_loss(recon, images)
loss.backward()
optimizer.step()The training is illustrated below.
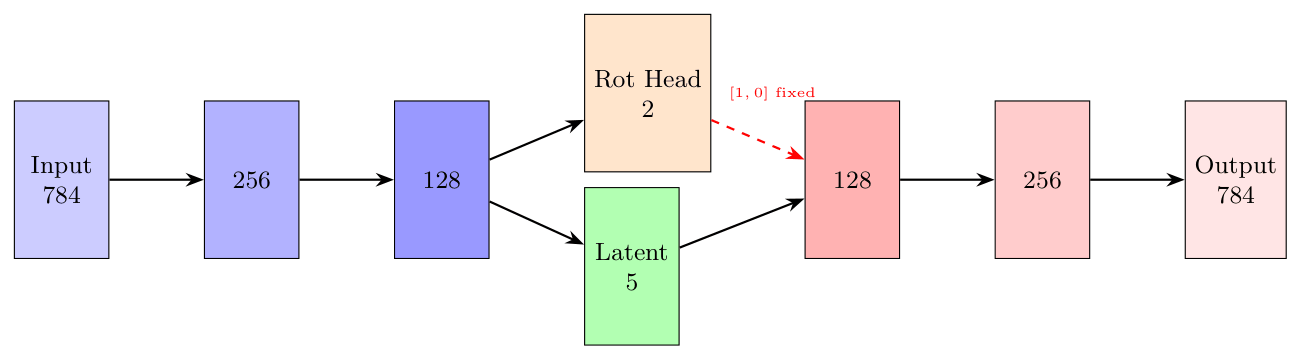
This taught the model to capture the essentials in the latent space.
In the next step we do something very explicit. We freeze encoder altogether and train the decoder. We do this by taking input images, rotating them by \(\theta\) (that we encode in the rotation head) and teach decoder to do the actual rotation.
Here "freeze" means the encoder parameters are not trained. We still use the forward process in full, but optimization is done only on rotation head and decoder.
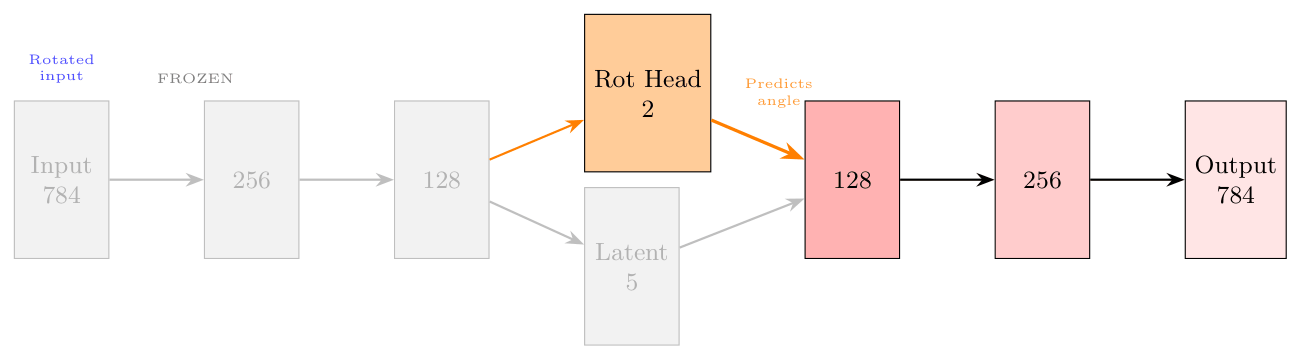
In python.
model = TypedAE().to(device)
model.load_state_dict(checkpoint['model_state_dict'])
# FREEZE ENCODER
for param in model.encoder_backbone.parameters():
param.requires_grad = False
for param in model.head_latent.parameters():
param.requires_grad = False
for param in model.head_rot.parameters():
param.requires_grad = False
# Only decoder learns
optimizer = optim.Adam(model.decoder.parameters(), lr=1e-3)
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
for epoch in range(epochs):
model.train()
total_loss = 0
for batch_idx, (images, labels) in enumerate(tqdm(train_loader, desc=f"Epoch {epoch+1}/{epochs}")):
images = images.to(device)
optimizer.zero_grad()
with torch.no_grad():
# Encode original image
h = model.encoder_backbone(images.view(images.size(0), -1))
z_latent = model.head_latent(h)
# Random rotation for each image
angles_rad = (torch.rand(images.size(0)) * 2 * np.pi).to(device) # 0-360°
z_rot = torch.stack([torch.cos(angles_rad), torch.sin(angles_rad)], dim=1)
# Decode with given theta
z_combined = torch.cat([z_rot, z_latent], dim=-1)
recon = model.decoder(z_combined).view(images.size(0), 1, 28, 28)
# Target: rotated image
target = rotate_image_batch(images, angles_rad)
# Loss: decoder must produce the rotated image
loss = nn.functional.mse_loss(recon, target)
loss.backward()
optimizer.step()
Next we need to ensure that encoder and decoder "speak the same language". Now, for the first time, encoder sees rotated images. This phase enforces it to NOT learn the angle because the angle is fed to the latent in a separate latent dimension. Second, we need the encoder to start to understand the angle the figure is rotated with.
The third phase aligns encoder and decoder.
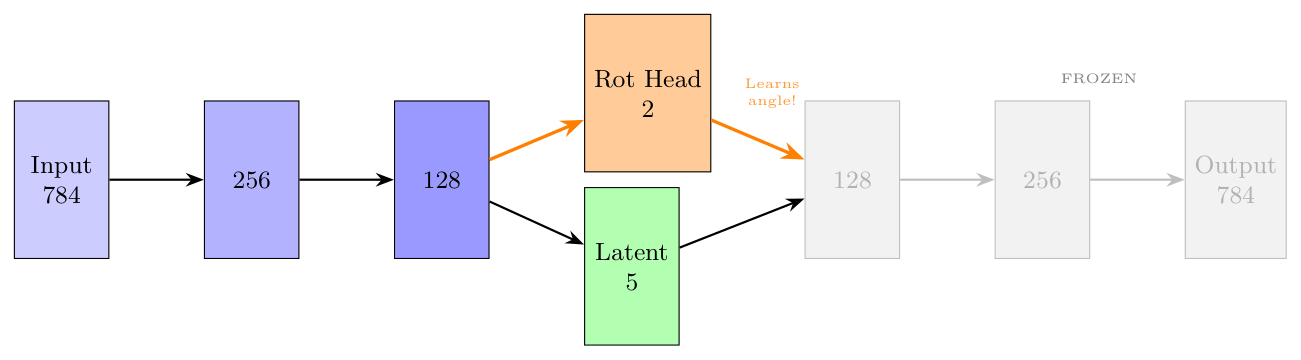
And the training.
# Freeze decoder
for param in model.decoder.parameters():
param.requires_grad = False
# Release encoder (esp. rotation head)
for param in model.encoder_backbone.parameters():
param.requires_grad = True # Try false to see the effect
for param in model.head_latent.parameters():
param.requires_grad = True # Try false to see the effect
for param in model.head_rot.parameters():
param.requires_grad = True
optimizer = optim.Adam([
{'params': model.encoder_backbone.parameters()},
{'params': model.head_latent.parameters()},
{'params': model.head_rot.parameters()},
], lr=1e-3)
transform = transforms.Compose([transforms.ToTensor()])
...
for epoch in range(epochs):
...
for batch_idx, (images, labels) in enumerate(tqdm(train_loader, desc=f"Epoch {epoch+1}/{epochs}")):
...
# Rotate with random angle
angles_rad = (torch.rand(images.size(0)) * 2 * np.pi).to(device)
images_rotated = rotate_image_batch(images, angles_rad)
optimizer.zero_grad()
# Encode rotated image
h = model.encoder_backbone(images_rotated.view(images_rotated.size(0), -1))
z_latent = model.head_latent(h)
z_rot = model.head_rot(h) # We train the angle!
# Decode (frozen decoder)
z_combined = torch.cat([z_rot, z_latent], dim=-1)
recon = model.decoder(z_combined).view(images_rotated.size(0), 1, 28, 28)
# Losses
loss_recon = nn.functional.mse_loss(recon, images_rotated)
# Rotation loss: z_rot must match the angle
target_rot = torch.stack([torch.cos(angles_rad), torch.sin(angles_rad)], dim=1)
loss_rot = nn.functional.mse_loss(z_rot, target_rot)
loss = loss_recon + 1.0 * loss_rot
loss.backward()
optimizer.step()
The Result
This rather simple model works surprisingly well. When we encode an image we can control its angle via the rotation head and decode images in any angle we want. Try to run the code to see the results.
Some digits suffer from morphing or blurring.
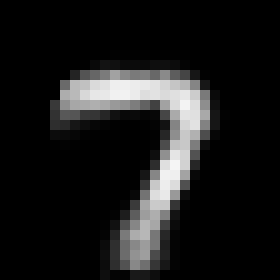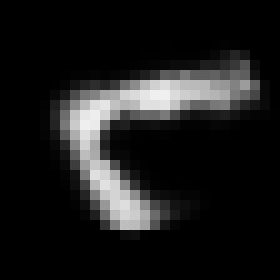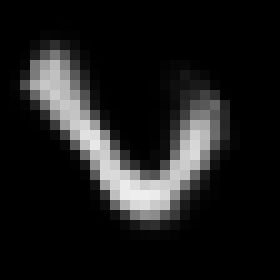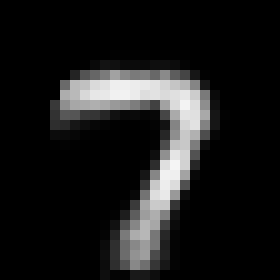
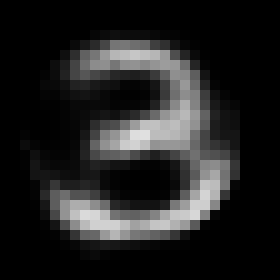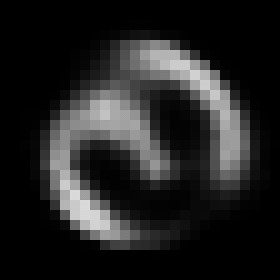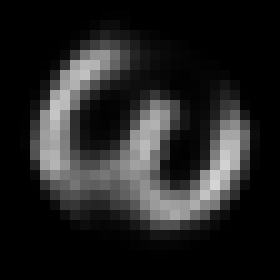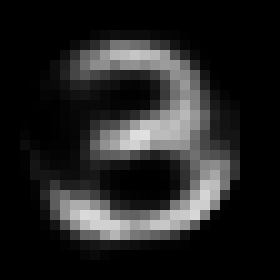
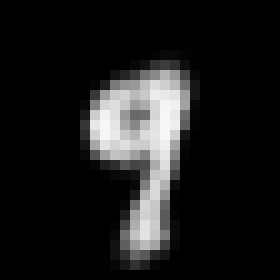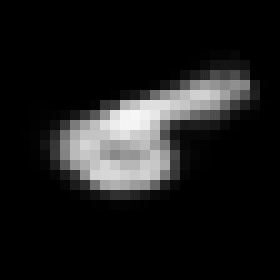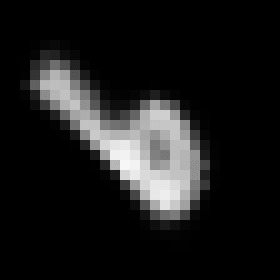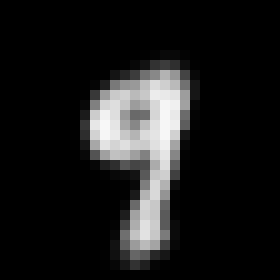
Conclusions
Our example is very simple and we really want to stress test it, Fashion dataset would be the way to go. Short tryouts with it didn't really work out too well. Increasing the model size and training epochs is most likely needed.
Anyway, we have now a solid proof about that the latent space can be made controllable.